IMAGE CLASSIFICATION
2024. 7. 11. 21:39ㆍ카테고리 없음
학습목차
A. 라벨정보 포함한 이미지 데이터셋 만들기
- 필요한 라이브러리 임포트
- 이미지 파일 가져오기
- os.listdir과 PIL.Image 이용하여 이미지 읽기
- 이미지 라벨링 포함해서 Class별 이미지 리스트 만들기
- Train/Test 데이터셋 만들기
B. Build Model
- Build Model
- Callback
- 모델 학습
- 성능 그래프
- Predict
C. image_dataset_from_directory 이용하여 데이터셋 만들기
- 필요한 라이브러리 임포트
- 이미지 파일 가져오기
- 이미지 파일 하나 읽어 이미지 보기
- Data Preprocess : image_dataset_from_directory 이용하여 한번에 처리
D. 모델링
- Build Model : Functional API
- Callback
- 모델 학습
- 성능 그래프
- Predict
E. MobileNet Transfer Learning & Fine-tuning 모델링
A. 라벨정보 포함한 이미지 데이터셋 만들기
1. 필요한 라이브러리 임포트
import os
from glob import glob
from PIL import Image
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
2. 이미지 파일 가져오기
# 약 3,700장의 꽃 사진 데이터세트를 사용합니다.
# 아래 데이터 가져오기 그냥 사용합니다.
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)- tf.keras.utils.get_file: 이 함수는 주어진 URL에서 파일을 다운로드하고, 필요하다면 압축을 해제(untar)합니다.
- 'flower_photos': 다운로드된 파일을 저장할 기본 파일 이름입니다.
- origin=dataset_url: 파일을 다운로드할 URL입니다.
- untar=True: 다운로드된 파일이 압축 파일일 경우, 이를 자동으로 해제합니다.
이 함수는 압축 파일을 다운로드하여 지정된 디렉토리에 압축을 해제하고, 그 디렉토리의 경로를 반환합니다.
- pathlib.Path: 문자열로 된 파일 경로를 Path 객체로 변환합니다. 이 객체는 파일 시스템 경로 작업을 더 쉽게 하고, 플랫폼 독립적인 경로 조작을 가능하게 합니다.
# 이미지 패스 확인
data_dir
## Output:PosixPath('/root/.keras/datasets/flower_photos')
# 이미지 폴더 밑의 폴더 확인
!ls -l /root/.keras/datasets/flower_photos/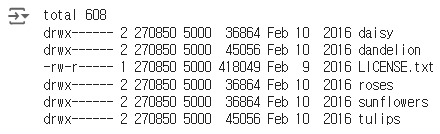
# daisy 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/daisy | grep jpg | wc -l
## 633
# dandelion 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/dandelion | grep jpg | wc -l
## 898
# roses 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/roses | grep jpg | wc -l
## 641
# sunflowers 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/sunflowers | grep jpg | wc -l
## 699
# tulips 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/tulips | grep jpg | wc -l
# 7993. os.listdir과 PIL.Image 이용하여 이미지 읽기
# 이미지 패스 지정
daisy_path = '/root/.keras/datasets/flower_photos/daisy/'
dandelion_path = '/root/.keras/datasets/flower_photos/dandelion/'
roses_path = '/root/.keras/datasets/flower_photos/roses/'
sunflowers_path = '/root/.keras/datasets/flower_photos/sunflowers/'
tulips_path = '/root/.keras/datasets/flower_photos/tulips/'# 이미지 패스의 파말 리스트 만들기
daisy_file = os.listdir(daisy_path)
dandelion_file = os.listdir(dandelion_path)
roses_file = os.listdir(roses_path)
sunflowers_file = os.listdir(sunflowers_path)
tulips_file = os.listdir(tulips_path)- os.listdir(path): 지정된 경로에 있는 모든 파일과 디렉토리의 이름을 리스트로 반환합니다.
# 이미지 파일 리스트 읽어보기
daisy_file[:2], roses_file[:2]# 위의 파일 리스트에서 2개씩 읽고 이미지 출력하기
for img_file in daisy_file[:2] :
img = Image.open(daisy_path + img_file).resize((224,224))
plt.title(img_file + ' : Positive')
plt.imshow(img)
plt.show()
for img_file in roses_file[:2] :
img = Image.open(roses_path + img_file).resize((224,224))
plt.title(img_file + ' : Negative')
plt.imshow(img)
plt.show()
4. 이미지 라벨링 포함해서 Class별 이미지 리스트 만들기
# Class 라벨 정의
class2idx = {'daisy' : 0, 'dandelion' : 1, 'roses' : 2, 'sunflowers' : 3, 'tulips' : 4}
idx2class = {0 : 'daisy', 1 : 'dandelion', 2 : 'roses', 3 : 'sunflowers', 4 : 'tulips'}# 수작업으로 이미지 리스트와 라벨 리스트 만들기
img_list = []
label_list = []
daisy_file = os.listdir(daisy_path)
for img_file in daisy_file :
img = Image.open(daisy_path + img_file).resize((128,128))
img = np.array(img)/255. # 이미지 스케일링
img_list.append(img)
label_list.append(0) # daisy : 0
dandelion_file = os.listdir(dandelion_path)
for img_file in dandelion_file :
img = Image.open(dandelion_path + img_file).resize((128,128))
img = np.array(img)/255. # 이미지 스케일링
img_list.append(img)
label_list.append(1) # dandelion : 1
roses_file = os.listdir(roses_path)
for img_file in roses_file :
img = Image.open(roses_path + img_file).resize((128,128))
img = np.array(img)/255. # 이미지 스케일링
img_list.append(img)
label_list.append(2) # roses : 2
sunflowers_file = os.listdir(sunflowers_path)
for img_file in sunflowers_file :
img = Image.open(sunflowers_path + img_file).resize((128,128))
img = np.array(img)/255. # 이미지 스케일링
img_list.append(img)
label_list.append(3) # sunflowers : 2
tulips_file = os.listdir(tulips_path)
for img_file in tulips_file :
img = Image.open(tulips_path + img_file).resize((128,128))
img = np.array(img)/255. # 이미지 스케일링
img_list.append(img)
label_list.append(4) # tulips : 2
- 리사이징(Resize): 이미지를 (128, 128)로 변환하여 모든 입력 데이터의 크기를 동일하게 하고 연산 효율성을 높이며 모델 아키텍처 요구사항을 충족합니다.
- 스케일링(Scaling): 이미지를 [0, 1] 범위로 정규화하여 학습 안정성과 성능을 향상시키고, 수치적 불안정성을 줄입니다.
# 이미지 리스트, 라벨 리스트루 numpy array 변경
img_list_arr = np.array(img_list)
label_list_arr = np.array(label_list)# 이미지 리스트, 라벨 리스트 shape 확인
img_list_arr.shape, label_list_arr.shape
## Output: ((3670, 128, 128, 3), (3670,))리스트를 넘파이 배열로 변환하는 이유
- 효율성:
- 메모리 효율성: 넘파이 배열은 리스트에 비해 메모리를 더 효율적으로 사용합니다. 배열은 동일한 데이터 타입을 연속된 메모리 블록에 저장하므로, 리스트보다 메모리 사용량이 적습니다.
- 연산 속도: 넘파이 배열은 리스트에 비해 연산 속도가 훨씬 빠릅니다. 넘파이는 C 언어로 구현되어 있어 저수준 연산을 최적화하고, 벡터화 연산(vectorized operations)을 지원합니다.
- 벡터화 연산(Vectorized Operations):
- 넘파이 배열을 사용하면 반복문 없이 배열 전체에 대해 수학적 연산을 수행할 수 있습니다. 이는 코드의 간결성과 실행 속도를 크게 향상시킵니다.
arr = np.array([1, 2, 3, 4]) arr = arr * 2 # 각 요소에 2를 곱함 ## 결과: [2, 4, 6, 8] - 딥러닝 프레임워크와 호환성:
- 딥러닝 프레임워크(예: TensorFlow, PyTorch)는 입력 데이터로 넘파이 배열을 요구하거나 넘파이 배열과의 호환성을 염두에 두고 설계되었습니다. 넘파이 배열을 사용하면 딥러닝 모델의 입력 데이터로 쉽게 사용할 수 있습니다.
- 다양한 기능:
- 넘파이는 다양한 수학적, 통계적 함수와 고급 배열 조작 기능을 제공합니다. 이를 통해 데이터 전처리, 변환, 분석 작업을 효율적으로 수행할 수 있습니다.
5. Train/Test 데이터셋 만들기
from sklearn.model_selection import train_test_split
X_train, X_test , y_train, y_test = train_test_split(img_list_arr, label_list_arr, test_size=0.3,
stratify=label_list_arr, random_state=41)
X_train.shape, X_test.shape , y_train.shape, y_test.shape- 'Stratify': 클래스 불균형이 있는 데이터셋에서 훈련 세트와 테스트 세트 모두에서 클래스 비율을 일정하게 유지하여 모델 평가의 편향을 줄입니다.
B. Build Model
1. Build Model
# Sequential 모델 정의
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(32, kernel_size=(5,5), strides=(1,1), padding='same', activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
model.add(Conv2D(64,(2,2), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(5, activation='softmax'))Conv2D와 MaxPooling2D의 원리와 과정
Conv2D (2D Convolutional Layer)
원리:
- Conv2D 레이어는 이미지의 특징(특성)을 추출하는 역할을 합니다.
- 작은 크기의 필터(커널)를 사용하여 이미지 전체를 스캔하면서, 이미지의 작은 영역과 필터의 값들을 곱하고 더한 결과를 출력합니다. 이 과정을 "합성곱(convolution)"이라고 합니다.
과정:
- 필터 선택: 예를 들어, 3x3 크기의 필터(커널)가 있다면, 이 필터는 3x3 크기의 값(가중치)을 가집니다.
- 스캔: 필터를 이미지의 좌측 상단부터 우측 하단까지 한 칸씩 이동(슬라이딩)하면서, 이미지의 작은 영역과 필터를 곱하고 그 결과를 더합니다.
- 출력: 각 위치에서 계산된 결과는 새로운 이미지(출력 특징 맵)의 한 픽셀이 됩니다. 이 과정을 통해 필터는 이미지의 특정 특징(예: 경계, 색상 변화 등)을 추출합니다.
MaxPooling2D (2D Max Pooling Layer)
원리:
- MaxPooling2D 레이어는 이미지의 크기를 줄이고, 계산량을 감소시키며, 중요한 특징을 강조하는 역할을 합니다.
- 작은 영역(예: 2x2)에서 가장 큰 값을 선택하여 새로운 이미지(풀링 맵)를 만듭니다.
과정:
- 영역 선택: 예를 들어, 2x2 크기의 영역을 선택합니다.
- 최대값 선택: 선택된 2x2 영역 내에서 가장 큰 값을 선택합니다.
- 이동: 이 과정을 필터와 유사하게, 이미지의 좌측 상단부터 우측 하단까지 한 칸씩 이동하며 반복합니다.
- 출력: 각 2x2 영역의 최대값이 새로운 이미지의 한 픽셀이 됩니다. 이를 통해 이미지 크기가 줄어들고, 중요한 특징만 남게 됩니다.
왜 Conv2D 다음에 MaxPooling2D가 오는지
목적과 이유:
- 특징 추출 후 압축:
- Conv2D 레이어는 이미지의 중요한 특징(엣지, 텍스처 등)을 추출합니다.
- 이러한 특징을 추출한 후, MaxPooling2D 레이어를 사용하여 특징 맵을 압축하고 중요한 정보만 남깁니다. 이를 통해 모델의 복잡성을 줄이고, 연산 속도를 높이며, 과적합(overfitting)을 방지할 수 있습니다.
- 차원 축소:
- MaxPooling2D는 이미지의 크기를 줄여 차원을 축소합니다. 이는 메모리 사용량과 계산량을 줄이는 데 중요합니다. 예를 들어, 2x2 풀링을 사용하면 이미지 크기가 절반으로 줄어듭니다.
- 변동성 감소:
- MaxPooling2D는 입력 데이터의 작은 변동에 대한 민감성을 감소시킵니다. 이는 모델이 좀 더 일반화된 특징을 학습하도록 도와줍니다.
요약
- Conv2D: 이미지의 중요한 특징을 추출합니다.
- MaxPooling2D: 특징 맵의 크기를 줄이고, 중요한 정보를 강조하며, 계산 효율성을 높입니다.
- 조합의 이유: Conv2D가 특징을 추출한 후, MaxPooling2D가 이를 압축하여 모델의 성능을 최적화하고, 연산량을 줄이며, 과적합을 방지하기 위해 사용됩니다.
# 모델 컴파일
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate), # Optimization
loss='sparse_categorical_crossentropy', # Loss Function
metrics=['accuracy']) # Metrics / Accuracymodel.summary()- 다중클래스/레이블 인코딩인 경우: sparse_categorical_crossentropy
- 원핫인코딩인 경우: categorical_crossentropy
손실함수와 평가지표
- 손실 함수: 모델의 학습 과정에서 예측 오류를 수치화하여 최소화하려는 대상입니다.
- 평가 지표: 모델의 성능을 평가하고, 특히 학습 과정 중과 학습 후에 모델의 품질을 모니터링하는 데 사용됩니다.
- 관계: 손실 함수 값이 낮아질수록 일반적으로 모델의 예측 성능이 좋아지지만, 정확도와 항상 일치하지는 않으며, 특히 데이터가 불균형하거나 모델이 과적합된 경우에 주의가 필요합니다.
손실 함수와 평가 지표를 함께 사용하여 모델의 학습과 평가를 균형 있게 진행하는 것이 중요합니다. 이를 통해 모델이 학습 데이터와 테스트 데이터에서 모두 좋은 성능을 발휘할 수 있도록 합니다.
2. Callback
# callback : EarlyStopping, ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5)
# ModelCheckpoint
checkpoint_path = "my_checkpoint.ckpt"
checkpoint = ModelCheckpoint(filepath=checkpoint_path,
save_best_only=True,
monitor='val_loss',
verbose=1)
- EarlyStopping: 검증 손실이 개선되지 않을 때 훈련을 조기에 중지하여 과적합을 방지하고 훈련 시간을 절약합니다.
- ModelCheckpoint: 훈련 과정 중 가장 성능이 좋은 모델을 저장하여, 최적의 모델을 나중에 사용할 수 있도록 보관합니다.
3. 모델 학습
# num_epochs = 10
# batch_size = 32
# 모델 학습(fit)
history = model.fit(
X_train, y_train ,
validation_data=(X_test, y_test),
epochs=num_epochs,
batch_size=batch_size,
callbacks=[es, checkpoint]
)
4. 성능 그래프
history.history.keys()
## Output: dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Model Accuracy')
plt.show()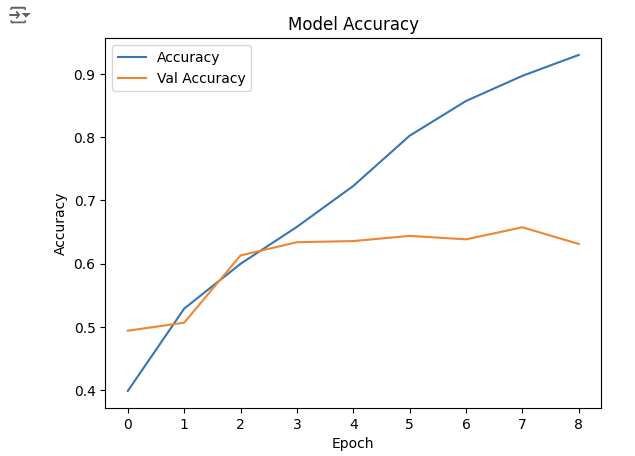
5. Predict
# Test 데이터로 성능 예측하기
i=1
plt.figure(figsize=(16, 8))
for img, label in zip(X_test[:8], y_test[:8]):
# 모델 예측(predict)
pred = model.predict(img.reshape(-1,128, 128, 3))
pred_t = np.argmax(pred)
plt.subplot(2, 4, i)
plt.title(f'True Value:{label}, Pred Value: {pred_t}')
plt.imshow(img)
plt.axis('off')
i = i + 1np.argmax(pred)는 모델의 예측 결과에서 가장 높은 확률 값을 가진 클래스의 인덱스를 반환합니다. 이를 통해 모델이 가장 확신하는 클래스가 무엇인지 알 수 있습니다.
- 모델 예측 결과:
- 모델의 출력인 pred는 클래스별 확률을 나타내는 벡터입니다. 예를 들어, 클래스가 5개인 경우 모델의 출력은 [0.1, 0.3, 0.2, 0.1, 0.3]와 같은 형태가 됩니다.
- 가장 높은 확률을 가진 클래스:
- np.argmax(pred)는 이 확률 벡터에서 가장 큰 값의 인덱스를 반환합니다. 예를 들어, [0.1, 0.3, 0.2, 0.1, 0.3]에서 가장 큰 값은 0.3이며, 이 값의 인덱스는 1과 4입니다. np.argmax(pred)는 이 중 첫 번째로 가장 큰 값인 1을 반환합니다.
- 예측된 클래스:
- 반환된 인덱스는 모델이 예측한 클래스 레이블을 의미합니다. 이를 통해 모델이 입력 이미지에 대해 어떤 클래스를 예측했는지 알 수 있습니다.
C.image_dataset_from_directory 이용하여 데이터셋 만들기
1.필요한 라이브러리 임포트
from glob import glob
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
2.이미지 파일 가져오기
# 약 3,700장의 꽃 사진 데이터세트를 사용합니다.
# 아래 데이터 가져오기 그냥 사용합니다.
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)# 이미지 패스 확인
data_dir# 이미지 폴더 밑의 폴더 확인
!ls -l /root/.keras/datasets/flower_photos/# daisy 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/daisy | grep jpg | wc -l
# dandelion 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/dandelion | grep jpg | wc -l
# roses 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/roses | grep jpg | wc -l
# sunflowers 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/sunflowers | grep jpg | wc -l
# tulips 폴더 안의 이지미 갯수
!ls -l /root/.keras/datasets/flower_photos/tulips | grep jpg | wc -l
3. 이미지 파일 하나 읽어 이미지 보기
# 이미지 패스 지정
daisy_path = '/root/.keras/datasets/flower_photos/daisy/'
# 이미지 패스의 파말 리스트 만들기
daisy_file = os.listdir(daisy_path)
# 이미지 파일 리스트 읽어보기
daisy_file[:2]
# 위의 파일 리스트에서 2개씩 읽고 이미지 출력하기
for img_file in daisy_file[:2] :
img = Image.open(daisy_path + img_file).resize((224,224))
plt.title(img_file + ' : Positive')
plt.imshow(img)
plt.show()
4. Data Process
image_dataset_from_directory 이용하여 자동으로 이미지 데이터셋 생성, 라벨링 한꺼번에 처리 할수 있다.
# 하이터 파라미터 정의
input_shape = (224, 224, 3)
batch_size = 32
num_classes = 5# 이미지 패스 지정
img_path ='/root/.keras/datasets/flower_photos/'# image_dataset_from_directory 함수 활용하여
# 이미지 폴더 밑의 이미지들에 대해 원핫인코딩된 labeling수행, 이미지 배치, 셔플 수행
# Train Dataset 만들기
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory=img_path,
label_mode="categorical", # binary , categorical
batch_size=batch_size,
image_size=(224, 224), # 사이즈 확인
seed=42,
shuffle=True,
validation_split=0.2,
subset="training" # One of "training" or "validation". Only used if validation_split is set.
)
# TestDataset 만들기
test_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory=img_path,
label_mode="categorical", # binary , categorical
batch_size=batch_size,
image_size=(224, 224), # 사이즈 확인
seed=42,
validation_split=0.2,
subset="validation" # One of "training" or "validation". Only used if validation_split is set.
)
## Output: Found 3670 files belonging to 5 classes.
## Output: Using 2936 files for training.
## Output: Found 3670 files belonging to 5 classes.
## Output: Using 734 files for validation.
## image_dataset_from_directory는 레이블을 원핫 인코딩으로 인코딩하기 때문에 모델 컴파일 부분에 loss function을 categorical_crossentropy로 설정해야 한다.
## 리스케일링은 안 해주기 때문에 모델링 부분에서 스케일링을 추가시켜주자.
파라미터 설명
- directory:
- img_path: 이미지 데이터가 저장된 폴더의 경로입니다. 이 폴더는 하위 폴더들(각 클래스에 해당하는 폴더)을 포함하고 있어야 합니다.
- label_mode:
- "categorical": 레이블을 원핫 인코딩 형태로 반환합니다. 다른 옵션으로는 "binary" (이진 레이블)와 None (레이블 없음)이 있습니다.
- batch_size:
- batch_size: 각 배치에서 사용할 이미지의 개수를 정의합니다. 이전에는 모델 학습 부분에서 batch를 정해줬는데, 이 함수는 딥러닝에서 나누어 학습할 수 있도록 미리 데이터 세팅 부분에서 batch_size로 나누어준다.
- image_size:
- (224, 224): 모든 이미지를 (224, 224) 크기로 리사이즈합니다. 이는 모델 입력 크기와 일치하도록 하기 위함입니다.
- seed:
- 42: 무작위성을 제어하기 위한 시드 값입니다. 동일한 시드 값을 사용하면 동일한 셔플링 결과를 얻을 수 있습니다.
- shuffle:
- True: 데이터셋을 셔플링하여 모델이 학습 데이터의 순서에 의존하지 않도록 합니다.
- validation_split:
- 0.2: 전체 데이터셋 중 20%를 검증용 데이터로 사용합니다.
- subset:
- "training": 데이터셋을 학습용으로 분할합니다. validation_split이 설정된 경우, subset 파라미터는 "training" 또는 "validation" 중 하나여야 합니다.
# 이런 방법도 있음
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rescale=1./255,
validation_split=0.2
)
train_generator = datagen.flow_from_directory(
img_path,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
subset='training'
)
validation_generator = datagen.flow_from_directory(
img_path,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
subset='validation'
)# Class 이름 확인
train_ds.class_names
## ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']# 40,000건 중에서 32,000건 Train 사용. test용으로 8,000건 사용
len(train_ds) * 32 , len(test_ds) * 32
## (2944, 736)- train_ds와 test_ds의 길이는 각각 배치의 수를 나타냅니다. 각 배치에는 32개의 이미지가 포함되어 있으므로, 전체 이미지 수를 계산하려면 배치 수에 배치 크기를 곱해야 합니다.
batch_img, batch_label = next(iter(train_ds))
batch_img.shape, batch_label.shape
## Output: (TensorShape([32, 224, 224, 3]), TensorShape([32, 5]))# 샘플 이미지 확인
i = 0
for batch_img, batch_label in train_ds.take(1):
if i == 0 :
print(batch_img[i].shape)
plt.imshow(batch_img[i]/255)
i = i + 1
- train_ds 데이터셋에서 첫 번째 배치를 가져옵니다. take(1)은 데이터셋에서 지정된 수의 배치를 가져오는 함수입니다. 여기서는 첫 번째 배치를 가져옵니다.
- plt.imshow(batch_img[i]/255): 첫 번째 이미지를 시각화합니다. 이미지를 255로 나누는 이유는 원래 픽셀 값이 0에서 255 사이의 정수 값인 경우, 이를 0에서 1 사이의 부동 소수점 값으로 변환하여 Matplotlib에서 올바르게 시각화할 수 있도록 하기 위함입니다.
D. Build Model
1. Build Model
# Hyperparameter Tunning
num_epochs = 10
batch_size = 32
learning_rate = 0.001
dropout_rate = 0.5
input_shape = (224, 224, 3) # 사이즈 확인
num_classes = 5from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Rescaling
model = Sequential()
model.add(Rescaling(1. / 255)) # 이미지 Rescaling. 없이 하면 성능이 안나옴.
model.add(Conv2D(32, kernel_size=(5,5), strides=(1,1), padding='same', activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
model.add(Conv2D(64,(2,2), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(5, activation='softmax'))# Model compile
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate), # Optimization
loss='categorical_crossentropy', # Loss Function
metrics=['accuracy']) # Metrics / Accuracy- 원핫 인코딩을 했기 때문에 loss = 'categorical_crossentropy'로 설정해야 한다.
2. Callback
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=3)
# ModelCheckpoint
checkpoint_path = "my_checkpoint.ckpt"
checkpoint = ModelCheckpoint(filepath=checkpoint_path,
save_best_only=True,
monitor='val_loss',
verbose=1)
3. 모델 학습
# image_dataset_from_directory 이용하여 데이터 만들었을때 아래와 같이 학습 진행
# num_epochs = 10
# 모델 학습(fit)
history = model.fit(
train_ds,
validation_data=(test_ds),
epochs=10,
callbacks=[es, checkpoint]
)4. 성능 그래프
history.history.keys()
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Model Accuracy')
plt.show()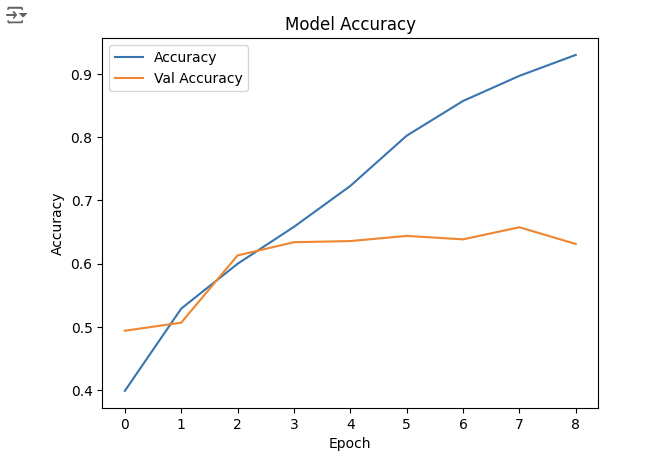
5. Predict
len(test_ds) * 32
# 배치사이즈 이미지/라벨 가져오기
batch_img , batch_label = next(iter(test_ds))
type(batch_img), batch_img.shape
# Test 데이터로 성능 예측하기
i = 1
plt.figure(figsize=(16, 30))
for img, label in list(zip(batch_img, batch_label)):
pred = model.predict(img.numpy().reshape(-1, 224,224,3), verbose=0)
pred_t = np.argmax(pred)
plt.subplot(8, 4, i)
plt.title(f'True Value:{np.argmax(label)}, Pred Value: {pred_t}')
plt.imshow(img/255) # 이미지 픽셀값들이 실수형이므로 0~1 사이로 변경해야 에러 안남
i = i + 1
E. MobileNet Transfer Learning & Fine-tuning 모델링
1. Build Model
# 케라스 applicatioins에 어떤 종류의 모델 있는지 확인
dir(tf.keras.applications)
# 사전 훈련된 모델 MobileNetV2에서 기본 모델을 생성합니다.
# 아래와 같은 형식을 MobileNetV2 Transfer Learning 사용하며 됩니다.
base_model = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), weights='imagenet', include_top=False)base_model.summary()
# tf.keras.applications.MobileNetV2 모델은 [-1, 1]의 픽셀 값을 예상하지만 이 시점에서 이미지의 픽셀 값은 [0, 255]입니다.
# MobileNetV2 모델에서 제대로 수행하기 위해 크기를 [-1, 1]로 재조정해야 합니다.(안하고 수행해도 성능 잘 나옴)
# 방법 2가지 있음
# 첫번째 방법 : preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
# 두번째 방법 : rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)# MobileNet V2 베이스 모델 고정하기
base_model.trainable = False
- base_model.trainable = False: 사전 훈련된 모델의 가중치를 고정하여 학습되지 않도록 설정합니다.
- 이유: 기존 가중치를 유지하여 특징 추출기로 사용하고, 새로운 분류기를 학습시켜 훈련 시간을 단축하고 과적합을 방지합니다.
# 모델 구축 : 이미지 픽셀값 조정 수행하기(Rescaling) --> 성능 더 잘 나옴.
inputs = tf.keras.Input(shape=(224, 224, 3))
x = tf.keras.layers.Rescaling(1./127.5, offset=-1)(inputs)
x = base_model(x, training=False)
x = tf.keras.layers.GlobalAveragePooling2D()(x) # 3차원(7, 7, 1280) --> 1차원(1280)으로 줄이기 : GlobalAveragePooling2D
output = tf.keras.layers.Dense(5, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=output)
model.summary()- tf.keras.layers.Rescaling: 이미지의 픽셀 값을 재조정하는 레이어입니다. 여기서는 픽셀 값을 [-1, 1] 범위로 변환합니다.
- 1./127.5: 원래의 픽셀 값(0~255)을 127.5로 나누어 0~2 범위로 스케일링합니다.
- offset=-1: 0~2 범위를 -1~1 범위로 변환하기 위해 -1을 더합니다.
- base_model: 사전 훈련된 MobileNetV2 모델입니다. training=False로 설정하여 이 레이어가 추론 모드에서 실행되도록 합니다. 이를 통해 사전 훈련된 가중치를 고정(freeze)하고, 새로운 데이터셋에 대해 학습되지 않도록 합니다.
- GlobalAveragePooling2D: 2차원 특징 맵을 평균 풀링하여 1차원 벡터로 변환합니다. 여기서 입력이 (7, 7, 1280) 크기라면, 출력은 (1280,) 크기의 벡터가 됩니다. 이는 Dense 레이어에 입력하기 위해 차원을 줄이는 역할을 합니다.
여기서 GlobalAveragePooling2D를 사용하는 이유!
- Flatten: 단순히 다차원 텐서를 1차원 벡터로 변환합니다. 주로 Dense 층과 바로 연결할 때 사용되며, 파라미터 수가 크게 증가할 수 있습니다. It is like 네모난 그림을 잘라서 한 줄로 길게 만드는 것.
- GlobalAveragePooling2D: 각 채널의 평균을 계산하여 1차원 벡터로 변환합니다. 파라미터 수를 줄이고 과적합을 방지하며, 사전 훈련된 모델과 잘 맞습니다. It is like 네모난 그림의 각 칸마다 평균값을 구해서 중요한 정보만 남기는 것.
# 모델 compile
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate), # Optimization
loss='categorical_crossentropy', # Loss Function
metrics=['accuracy']) # Metrics / Accuracy
2. Callback
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=3)
# ModelCheckpoint
checkpoint_path = "my_checkpoint.ckpt"
checkpoint = ModelCheckpoint(filepath=checkpoint_path,
save_best_only=True,
monitor='val_loss',
verbose=1)
3. 모델 학습
# image_dataset_from_directory 이용하여 DataSet을 만들었으며
# num_epochs = 10
# batch_size = 32
history = model.fit(
train_ds,
validation_data = test_ds,
epochs=2,
callbacks=[es, checkpoint]
)
4. 성능 그래프
history.history.keys()
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Model Accuracy')
plt.show()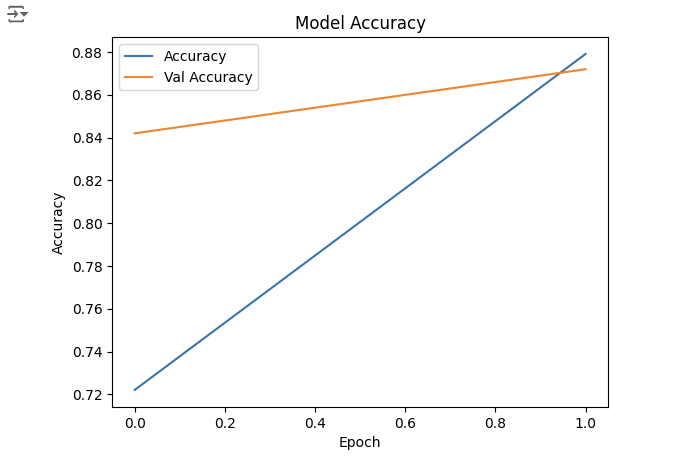
5. Predict
# Test Dataset의 전체 accuracy 구하기
from sklearn.metrics import accuracy_score
# 전체 데이터셋을 반복하며 예측 수행
y_true = []
y_pred = []
for images, labels in test_ds:
predictions = model.predict(images)
y_true.extend(tf.argmax(labels, axis=1).numpy())
y_pred.extend(tf.argmax(predictions, axis=1).numpy())
# accuracy 계산
accuracy = accuracy_score(y_true, y_pred)
print(f'Overall Test Accuracy: {accuracy:.4f}')# test_generator 샘플 데이터 가져오기
# 배치 사이즈 32 확인
batch_img, batch_label = next(iter(test_ds))
print(batch_img.shape)
print(batch_label.shape)
## Output: (32, 224, 224, 3)
## Output: (32, 5)# 이미지 rescale 되어 있는 상태
batch_img[0][0][:10]
# 높은 성능 보여줌
i = 1
plt.figure(figsize=(16, 30))
for img, label in list(zip(batch_img, batch_label)):
pred = model.predict(img.numpy().reshape(-1, 224,224,3), verbose=0)
pred_t = np.argmax(pred)
plt.subplot(8, 4, i)
plt.title(f'True Value:{np.argmax(label)}, Pred Value: {pred_t}')
plt.imshow(img/255) # 이미지 픽셀값들이 실수형이므로 0~1 사이로 변경해야 에러 안남
i = i + 1